FEP Workflow Tutorial¶
Level: Advanced
Time: 2-4 hours (+ computation time)
Topics: Relative binding free energy, hybrid topologies, lambda schedules, execution modes, analysis
This tutorial walks through the current PRISM FEP workflow using the 42-38 HIF-2α ligand pair.
Objectives¶
You will learn how to:
- prepare a ligand pair for PRISM FEP
- inspect atom mapping and the single topology
- understand how PRISM transforms the system across lambda windows
- run the generated bound and unbound legs
- choose between
standardandrepexexecution - analyze completed window data with BAR, MBAR, and TI
Recommended Path for a First FEP Run¶
If this is your first PRISM FEP calculation, keep the defaults unless you already know why you need something different:
- use the packaged
42-38example inputs and configs - build the scaffold
- run
run_fep.sh all - inspect
mapping.htmlbefore launching long production - analyze the completed
boundandunboundlegs withprism --fep-analyze
Prerequisites¶
- completed Basic Tutorial or equivalent PRISM familiarity
- GROMACS installed and available as
gmx - enough CPU/GPU resources for your chosen window schedule
- basic understanding of alchemical free-energy calculations
Note
Multiple GPUs improve throughput, but PRISM can still generate valid scaffolds for smaller GPU counts or CPU-only debugging workflows.
Background: The 42-38 System¶
We use the 42-38 ligand pair from HIF-2α:
- Ligand 42: reference ligand (state A)
- Ligand 38: mutant ligand (state B)
This pair is suitable for FEP because the chemical change is local and the ligands share a clear common scaffold.
Step 1: Download the Example Files¶
This tutorial uses a packaged 42-38 HIF-2α example with separate input/ and configs/ folders.
The ligands are provided as MOL2 files because that preserves bond order and atom typing information more reliably than plain ligand PDB files. The receptor remains a PDB file.
Or download them via command line:
mkdir -p prism_fep_tutorial/input prism_fep_tutorial/configs
cd prism_fep_tutorial
wget -O input/receptor.pdb https://raw.githubusercontent.com/AIB100/PRISM-Tutorial/main/docs/assets/examples/fep/42-38/input/receptor.pdb
wget -O input/42.mol2 https://raw.githubusercontent.com/AIB100/PRISM-Tutorial/main/docs/assets/examples/fep/42-38/input/42.mol2
wget -O input/38.mol2 https://raw.githubusercontent.com/AIB100/PRISM-Tutorial/main/docs/assets/examples/fep/42-38/input/38.mol2
wget -O configs/fep_gaff2.yaml https://raw.githubusercontent.com/AIB100/PRISM-Tutorial/main/docs/assets/examples/fep/42-38/configs/fep_gaff2.yaml
wget -O configs/config_gaff2.yaml https://raw.githubusercontent.com/AIB100/PRISM-Tutorial/main/docs/assets/examples/fep/42-38/configs/config_gaff2.yaml
Verify the files:
The packaged example uses:
- input/receptor.pdb for the receptor
- input/42.mol2 for ligand 42 (reference/state A)
- input/38.mol2 for ligand 38 (mutant/state B)
- configs/fep_gaff2.yaml for FEP-specific settings
- configs/config_gaff2.yaml for the general PRISM build configuration
Step 2: Review the FEP Configuration¶
The packaged files are copied from the real 42-38 fixture. fep_gaff2.yaml controls the FEP schedule, while config_gaff2.yaml provides the general PRISM build settings used alongside it.
A representative setup is:
mapping:
dist_cutoff: 0.6
charge_cutoff: 0.05
charge_common: mean
charge_reception: surround
lambda:
strategy: decoupled
distribution: nonlinear
quadratic_exponent: 2.0
windows: 32
coul_windows: 12
vdw_windows: 20
simulation:
equilibration_nvt_time_ps: 500
equilibration_npt_time_ps: 500
per_window_npt_time_ps: 100
production_time_ns: 2.0
dt: 0.002
temperature: 310
pressure: 1.0
execution:
mode: standard
num_gpus: 4
parallel_windows: 4
total_cpus: 40
use_gpu_pme: true
mdrun_update_mode: auto
replicas: 3
Key points for a first run:
| Item | Current behavior |
|---|---|
dist_cutoff: 0.6 |
Means 0.6 nm, not 0.6 Å. |
strategy: decoupled |
This is the recommended default for a first run. |
| Default windows | 32 total windows split as 12 Coulomb + 20 VDW windows. |
| CLI vs YAML | Use an explicit FEP YAML when you care about exact schedules. |
| File roles | fep_gaff2.yaml controls the FEP schedule; config_gaff2.yaml supplies the general build settings. |
| Repeat counts | FEP repeat directories come from top-level replicas in fep_gaff2.yaml (here 3). |
Step 3: Understand What the Lambda Windows Actually Do¶
For a first run, you usually do not need to change the default decoupled + nonlinear schedule. This step explains what PRISM is doing so the generated windows are easier to interpret. For the full parameter reference, see the FEP User Guide.
In PRISM's default decoupled schedule:
-
Coulomb stage
coul-lambdasmove from0 -> 1vdw-lambdasstay at0
-
VDW stage
coul-lambdasstay at1vdw-lambdasmove from0 -> 1
At the same time:
| Lambda vector | Current behavior |
|---|---|
bonded-lambdas |
Follow the Coulomb schedule. |
mass-lambdas |
Follow the Coulomb schedule. |
So PRISM does not simply scale a single scalar lambda through the whole transformation. It writes separate lambda vectors into each MDP.2 3
If you choose:
strategy: coupled- Coulomb and VDW transform together across all windows
strategy: custom- you must provide both
custom_coul_lambdasandcustom_vdw_lambdas - if one custom array is shorter than the other, PRISM pads the shorter one with its final value
The following figure visualizes the three lambda schedule strategies:
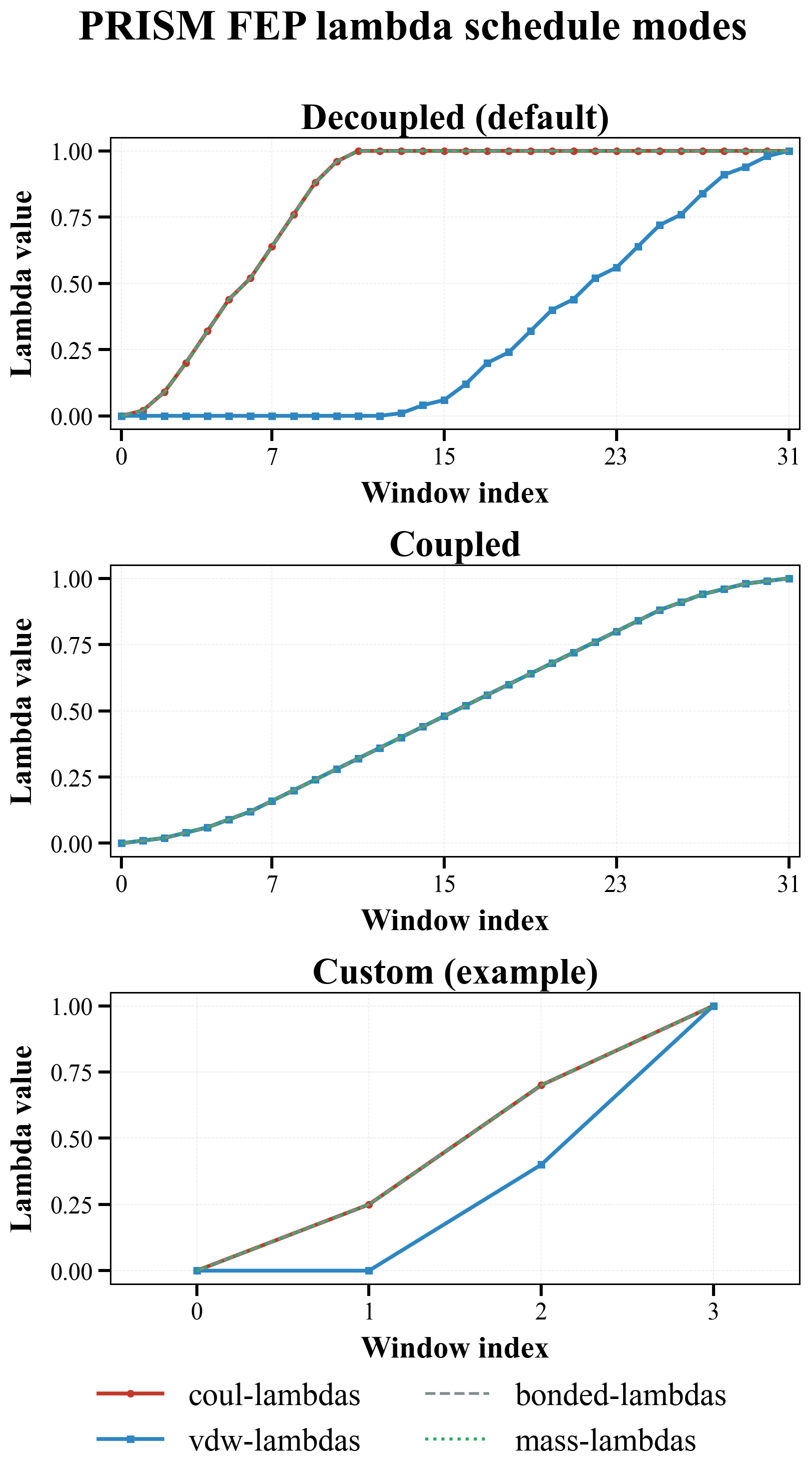
Figure interpretation¶
- Decoupled: The default two-stage approach — electrostatics (red line) finish first (windows 0-11), then van der Waals (blue squares) take over (windows 12-31)
- Coupled: Both red and blue lines move together from 0 to 1 across all windows
- Custom: A user-defined example where you control exactly when each term transforms
For most users, the default decoupled + nonlinear schedule is the right starting point; only tune these settings if you have a specific reason to reshape the lambda path.
Supported schedule distributions are shown below. For a first run, keep the default nonlinear setting unless you have a specific reason to reshape the lambda path:
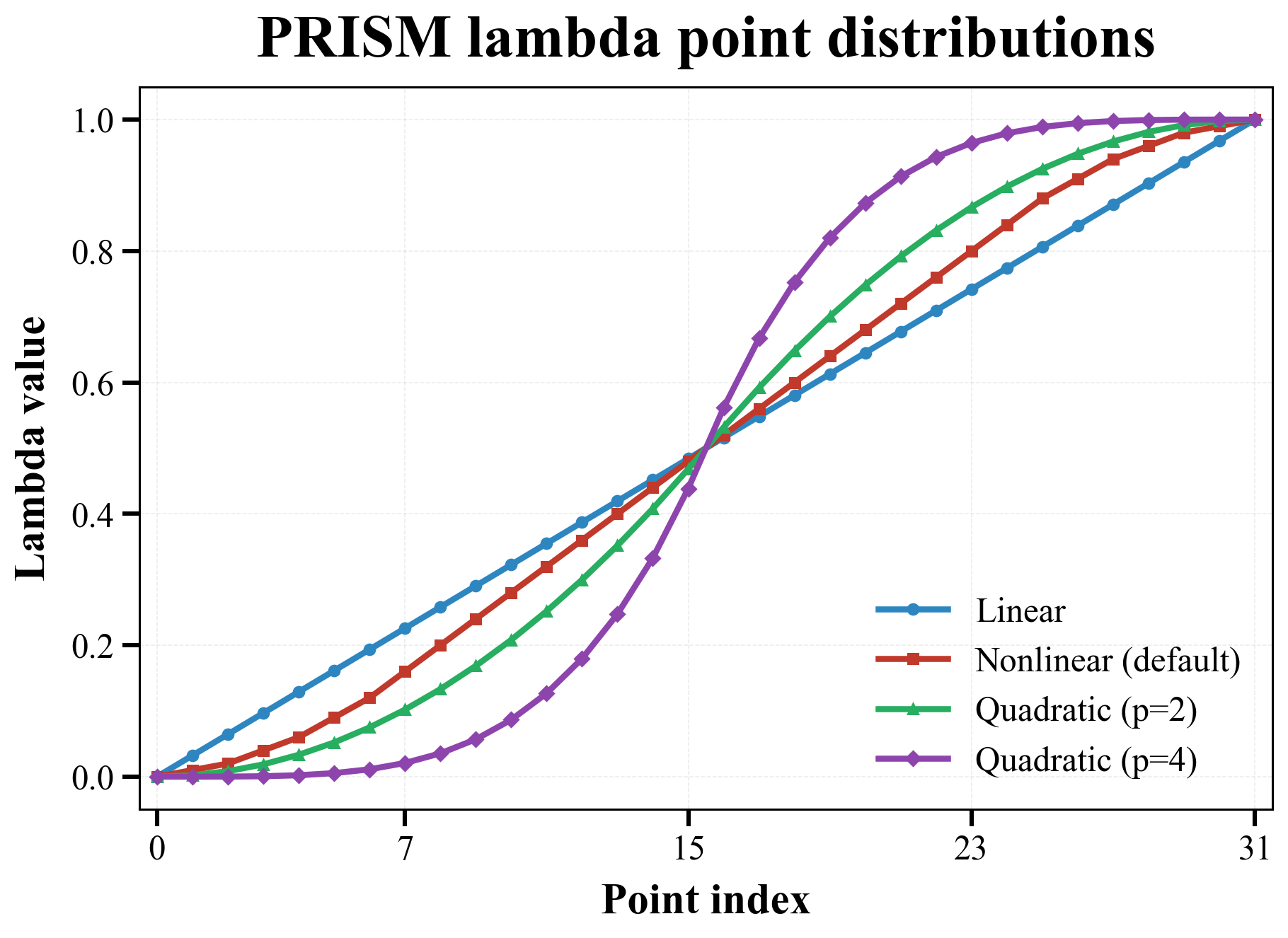
| Distribution | Meaning |
|---|---|
linear |
Uniform spacing. |
nonlinear |
PRISM's default empirical endpoint-dense reference schedule. |
quadratic |
Empirical power-law endpoint bias controlled by quadratic_exponent. Use custom lambda arrays if you need exact control. |
Interpreting charge redistribution¶
For a first run, you usually do not need to change the default charge settings. The main idea is simply to keep the perturbation local and easier to sample. By keeping electrostatic properties consistent in the common (shared) regions of the ligands, we often:
- Reduce the magnitude of the perturbation → better convergence
- Lower statistical uncertainty → more reliable \(\Delta G\) estimates
- Maintain physical consistency → common regions behave similarly in both states
The following figure visualizes the charge redistribution strategies:
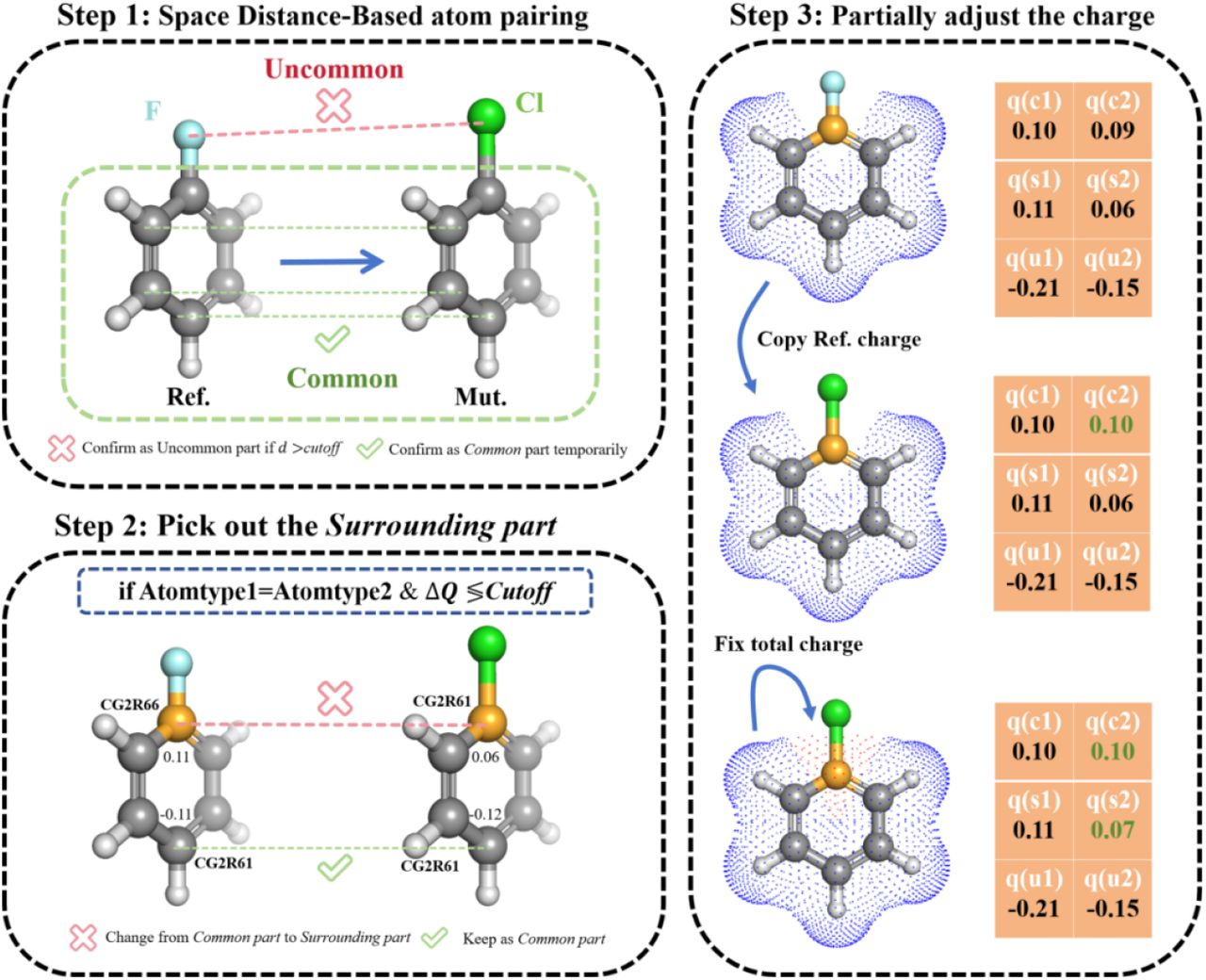
For parameter details, see the table in Which options should users know about first?.
Step 4: Build the FEP Scaffold¶
prism input/receptor.pdb input/42.mol2 -o amber14sb_OL15-mut_gaff2 \
--fep \
--mutant input/38.mol2 \
--ligand-forcefield gaff2 \
--forcefield amber14sb_OL15 \
--fep-config configs/fep_gaff2.yaml \
--config configs/config_gaff2.yaml
Expected outputs:
amber14sb_OL15-mut_gaff2/GMX_PROLIG_FEP/common/hybrid/with single topology and mapping artifactsbound/repeat1/ ... repeat3/andunbound/repeat1/ ... repeat3/(because this example usesreplicas: 3)- root-level
run_fep.sh fep_scaffold.json
The scaffold is built in a fixed order: PRISM prepares the bound leg first, then builds the unbound leg using the bound-leg box vectors so that both legs start from the same box dimensions.
Important: the scaffold step already creates common/hybrid/mapping.html, so you can inspect the mapping before launching any MD.
Step 5: Inspect Chemical Correctness¶
At this stage, PRISM has already generated the mapping report.
You will find it at:
GMX_PROLIG_FEP/common/hybrid/mapping.html
Open the mapping report:
Check that:
- the transformed region is local and chemically sensible
- the common scaffold matches your expectation
- there are no obviously incorrect long-range swaps
If you need a machine-readable summary of the scaffold, you can also inspect fep_scaffold.json, but the mapping report is the main checkpoint at this stage.
Use this report to inspect:
- atom correspondence before any MD is run
- transformed, surrounding, and common classes in a chemically local context
- atom labels and charges if the mapping looks suspicious
- whether the single topology is worth testing further
The mapping report contains:
- a display toolbar for switching between FEP Classification and Element coloring, turning charges and labels on or off, resetting the view, exporting a PNG snapshot, jumping to the atom-details section, or printing the page
- two independently pannable and zoomable ligand drawings for side-by-side comparison
- a legend that lists the classification counts and the element color key
- hover tooltips that report the atom name, element, charge, classification, and mapped partner atom
- an atom-details table with atom names, elements, atom types, charges, and classifications for both ligands
First checkpoint: if the mapping report looks chemically implausible, stop here and correct the transformation before running production windows.
Step 6: Inspect the Generated Layout and Entry Points¶
Typical layout:
GMX_PROLIG_FEP/
├── run_fep.sh
├── fep_scaffold.json
├── common/
│ └── hybrid/
├── bound/
│ ├── repeat1/
│ ├── repeat2/
│ └── repeat3/
│ ├── build/
│ ├── input/
│ ├── mdps/
│ ├── run_prod_standard.sh
│ ├── run_prod_repex.sh
│ └── window_00/ ... window_31/
└── unbound/
├── repeat1/
├── repeat2/
└── repeat3/
├── build/
├── input/
├── mdps/
├── run_prod_standard.sh
├── run_prod_repex.sh
└── window_00/ ... window_31/
Important points:
run_fep.shis the main entry point for scaffold execution.run_prod_standard.shandrun_prod_repex.share leg-level production helpers thatrun_fep.shcalls after leg-level equilibration.fep_scaffold.jsonrecords the generated layout and key scaffold metadata.mdps/andwindow_*hold the generated window-specific inputs and production workspaces.
Step 5 answers is the chemistry plausible? Step 6 answers do I understand what was generated and what to run next?
For a fuller explanation of the scaffold layout, generated scripts, and per-window relaxation stages, see the FEP Calculations guide.
Step 7: Choose an Execution Mode¶
PRISM supports two production execution modes. The detailed execution model, resource behavior, and helper-script roles are documented in the FEP Calculations guide.
Standard mode¶
This is the usual default:
Behavior:
| Property | standard mode behavior |
|---|---|
| Window execution | Windows are independent. |
| Concurrency | Up to parallel_windows windows run concurrently. |
| GPU assignment | GPUs are assigned round-robin. |
| Best for | Simple throughput-oriented execution. |
Replica-exchange mode¶
Treat this as an advanced option. For a first tutorial run, stay with standard.
Summary:
| Property | repex mode behavior |
|---|---|
| Launch style | Production is launched with gmx_mpi -multidir across the generated window_* directories. |
| Best for | Lambda replica exchange instead of independent windows. |
Note
execution.parallel_windows matters in standard mode. In repex, the main switch is execution.mode: repex.
Step 8: Run Full Production¶
For a first tutorial run, keep execution.mode: standard and launch bash run_fep.sh all unless you specifically want to run only one leg or one replica.
After the scaffold and runtime configuration look correct:
If you need to run the legs separately:
run_fep.sh also accepts replica-specific targets such as bound1, unbound2, and bound1-3. For the full target syntax and runtime environment overrides (PRISM_FEP_MODE, PRISM_NUM_GPUS, PRISM_PARALLEL_WINDOWS, PRISM_OMP_THREADS, PRISM_TOTAL_CPUS, and PRISM_GPU_ID), see the Running FEP section.
If your scaffold contains multiple replicas, the master script also supports:
Step 9: Monitor Progress¶
If everything is working normally, you should see:
build/logs completing for the leg-level EM/NVT/NPT stageswindow_*directories filling withprod.*files anddhdl.xvg- analysis-ready bound and unbound legs once the production windows finish
Examples:
find bound/repeat1 -maxdepth 1 -type d -name 'window_*' | wc -l
ls bound/repeat1/window_00/
ls bound/ | grep '^repeat'
What to check:
| Item | Expected sign |
|---|---|
| EM | Completes with a reasonable final force. |
| NVT/NPT | Produce *.gro and *.cpt. |
| Window outputs | Each window_* directory produces prod.* and dhdl.xvg (the dhdl.xvg write frequency is controlled by output.nstdhdl, default 100 MD steps). |
| Logs | Contain Finished mdrun on rank 0. |
How to resume after interruption¶
run_fep.sh is designed to be rerunnable. If a leg was interrupted, rerun the same command and PRISM will reuse completed leg-level stages and skip production windows that already have prod.gro.
If you need to force a single window to rerun, remove the failed production outputs in that window_* directory and rerun the same leg command.
Step 10: Analyze Completed Windows¶
After production has created dhdl.xvg files, run the post-processing step:
prism --fep-analyze \
--bound-dir amber14sb_OL15-mut_gaff2/GMX_PROLIG_FEP/bound \
--unbound-dir amber14sb_OL15-mut_gaff2/GMX_PROLIG_FEP/unbound \
--estimator MBAR BAR TI \
--bootstrap-n-jobs 8 \
--output fep_results.html \
--json fep_results.json
Note
prism --fep-analyze accepts either a single repeat directory or a leg directory containing repeat* subdirectories. If you pass .../bound and .../unbound, the CLI auto-discovers all repeats and performs aggregated analysis across them. In practice, the bound and unbound legs should contain the same repeat set before you aggregate them.
For a first tutorial run, treat MBAR as the primary estimator and use BAR and TI as consistency checks.
PRISM supports three standard estimators:
| Estimator | What it does | When to use |
|---|---|---|
| TI (Thermodynamic Integration) | Integrates \(\partial H / \partial \lambda\) across windows | Smooth transformations with well-sampled gradients |
| BAR (Bennett Acceptance Ratio) | Compares neighboring window pairs | Standard FEP with adequate sampling |
| MBAR (Multistate BAR) | Reweights all data simultaneously | Most efficient; provides overlap matrix for quality checks |
The numerical analysis workflow is:
- read
dhdl.xvgtime series from each window - compute \(\Delta G_{\mathrm{bound}}\) and \(\Delta G_{\mathrm{unbound}}\) with uncertainty estimates
- report binding free energy as
$$ \Delta G_{\mathrm{bind}} = \Delta G_{\mathrm{unbound}} - \Delta G_{\mathrm{bound}} $$
- generate an HTML report with the analysis panels available for that run (for example MBAR overlap, convergence, repeat summaries, and estimator comparison when applicable)
Step 11: Validate the Numerical Report¶
For a first pass through the report, use this checklist:
- confirm that each analyzed window produced
dhdl.xvg - check MBAR overlap for obvious gaps between neighboring windows
- check convergence for late-time drift
- compare BAR / MBAR / TI and see whether they tell the same story within uncertainty
Open fep_results.html in a browser.
This file is written by the analysis step, either to the current working directory or to the path specified with --output.
Not every report shows every panel. In particular, the overlap matrix is MBAR-only, estimator comparison is most informative when you request more than one estimator, and repeat summaries appear only when multiple repeat* pairs are analyzed together.
Use the numerical report to check:
| Panel | When it appears | What to look for |
|---|---|---|
| Overlap matrix | MBAR analyses only. | Neighboring windows overlap adequately, with the strongest values near the diagonal and no obvious gaps between adjacent states. |
| Estimator agreement | When you request more than one estimator. | BAR, MBAR, and TI are broadly consistent within uncertainty. |
| Convergence | When time-convergence analysis succeeds. | Estimates stabilize as more data are accumulated; late-time curves should flatten rather than keep drifting. |
| Uncertainty | When bootstrap resampling is enabled and produces usable samples. | Bootstrap error bars are reasonable for the sampling length and small enough for the decision you care about. |
| Repeat summary | When you analyze more than one repeat* pair together. |
Repeat-level results tell a similar story and no single repeat is an obvious outlier. |
Interpret these panels together:
- Good MBAR overlap + stable convergence + consistent estimators usually means the result is trustworthy when those panels are present.
- Poor overlap often means your lambda schedule is too sparse or the perturbation is too large.
- Late-time drift in convergence plots usually means you still need more sampling.
- Estimator disagreement is a warning sign that the dataset may be undersampled or poorly overlapped.
- Repeat-to-repeat disagreement suggests that sampling noise may still dominate the final estimate.
Use this report to decide whether:
- the reported \(\Delta\Delta G\) is supported by adequate window overlap
- the estimate is stable rather than still drifting
- the estimator choice materially changes the conclusion
- additional sampling or a revised lambda schedule is needed
Result-validation checkpoint: do not interpret \(\Delta\Delta G\) without checking overlap, convergence, and estimator agreement.
Practical Follow-up Questions¶
Why are there so many window-level MDP files?¶
Because PRISM writes explicit per-window lambda schedules, plus short per-window equilibration stages (em_short, npt_short) before production.
Is --lambda-windows enough by itself?¶
Not if you want reproducibility. For serious FEP work, define lambda.strategy, distribution, and any stage counts explicitly in fep.yaml.
Why does PRISM redistribute charges during mapping?¶
FEP accuracy depends on minimizing the perturbation between ligands. If common (shared) atoms have very different charges in the two states, the alchemical transformation becomes larger and harder to converge:
- Larger perturbation → poorer convergence → higher uncertainty in \(\Delta G\)
- Smaller perturbation → better convergence → more reliable results
By using charge_common: mean and charge_reception: surround, PRISM keeps electrostatic properties consistent in shared regions, confining the major changes to the actual mutation site.2 3
Which options should users know about first?¶
These are the most important knobs:
| Parameter | Why it matters |
|---|---|
mapping.dist_cutoff |
Controls how permissive atom mapping is. |
mapping.charge_common |
Changes how shared atoms inherit charge information. |
mapping.charge_reception |
Changes where balancing charge is redistributed. |
lambda.strategy |
Chooses decoupled, coupled, or custom lambda behavior. |
lambda.distribution |
Controls where windows are denser or sparser. |
lambda.windows |
Sets the total schedule size. |
lambda.coul_windows |
Controls the Coulomb stage length in decoupled mode. |
lambda.vdw_windows |
Controls the VDW stage length in decoupled mode. |
simulation.per_window_npt_time_ps |
Sets the short per-window NPT relaxation before production. |
simulation.production_time_ns |
Sets per-window production length. |
execution.mode |
Chooses standard versus replica-exchange execution. |
execution.parallel_windows |
Sets standard-mode concurrency. |
execution.num_gpus |
Affects GPU allocation in generated scripts. |
execution.total_cpus / execution.omp_threads |
Control CPU/OpenMP layout. |
execution.use_gpu_pme |
Requests GPU PME in production helpers. |
execution.mdrun_update_mode |
Controls GPU/CPU update behavior in runtime commands. |
replicas |
Controls how many repeat directories are scaffolded. |
Troubleshooting¶
Mapping looks wrong¶
- prefer MOL2 or SDF if PDB loses bond-order information
- verify protonation and tautomer states before building
- inspect
mapping.htmlfirst
EM/NVT/NPT fails early¶
- inspect
common/hybrid/hybrid.itpandcommon/hybrid/mapping.html - inspect
build/em.log,build/nvt.log, andbuild/npt.log - if the failure only appears after you changed the scaffold or runtime settings, rebuild or rerun before launching long production
GPU memory is insufficient¶
- reduce
execution.parallel_windows - reduce
PRISM_NUM_GPUSif you are oversubscribing devices - rerun the same leg after adjusting the runtime resource overrides
Analysis CLI finds no windows or no dhdl.xvg¶
- pass either a repeat directory or a leg directory containing
repeat* - confirm that the bound and unbound legs contain the same repeat set before aggregated analysis
- confirm that each finished
window_*directory containsdhdl.xvg
How do I restart only failed work?¶
- rerun the same
run_fep.shcommand to resume a leg - to force a single window to rerun, remove the failed
prod.*outputs in thatwindow_*directory and launch the same leg again
Summary¶
You have now:
- built a PRISM FEP scaffold for the 42-38 pair
- inspected the atom mapping and single topology
- understood how PRISM transforms Coulomb and VDW terms across lambda windows
- run the production entry points
- seen the main execution and analysis options exposed to users
Additional Resources¶
- FEP User Guide — detailed reference for FEP configuration, scaffold structure, execution, and analysis.
- Configuration — broader PRISM configuration reference beyond the FEP-specific settings used here.
- Analysis Tools — post-processing guidance for trajectories, energies, convergence, and related analysis outputs.